最近一周在点评帮预订运营做Hive报表,写了有几百行SQL,各种join操作,比较坑的是Mapreduce job要跑十多分钟,测试测得吐血,感觉是时候整理一波SQL了

基本查询
WHERE(条件),BETWEEN,LIKE,AND,OR,IN,NOT
SELECT ID,Name,Age FROM Students WHERE Age BETWEEN 18 AND 20
SELECT ID,Name FROM Students WHERE Name LIKE '张%' OR Name LIKE '李%'
SELECT ID,Name FROM Students WHERE Age IN (18,19,20)
SELECT ID,Name FROM Students WHERE Name NOT LIKE '张%'
ORDER BY(排序)
功能:对需要查询后的结果集进行排序,ASC(升序,默认),DESC(倒序)
可以指定多列排序,每个排序字段可以指定排序规则,优先第一列排序,如果第一列相同则按照第二列排序,以此类推。
SELECT ID,Name,Score FROM Students ORDER BY Score DESC,ID ASC
AS(Alias),Distinct,MAX/MIN,SUM,AVG,COUNT,TOP
AS:可以为列名称和表名称指定别名
Distinct:查询时忽略重复值
MAX/MIN:返回最大值;SUM:查询某列合计值;AVG:返回某列平均值
COUNT:返回匹配指定条件的行数
TOP:用于规定要返回的记录的数目
SELECT DISTINCT(Score),Count(ID) FROM Student GROUP BY Score
SELECT TOP 3 ID,Name FROM Students ORDER BY Age DESC
GROUP BY
用于结合合计函数,根据一个或多个列对结果集进行分组。
在不使用聚合函数的时候,group by 子句中必须包含所有的列
group by 不允许直接使用select别名
-- 删除学生信息中重复记录
DELETE FROM Students WHERE ID NOT IN (SELECT MAX(ID) FROM Students GROUP BY ID,Name,Age,Sex,City,MajorID)
HAVING
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用
-- 查询总成绩在600分以上(包括600)的学生ID
SELECT StudentID FROM SC GROUP BY StudentID HAVING SUM(Score)>=600
CASE语句
计算条件列表,并返回多个可能结果表达式之一。CASE表达式有两种格式:
CASE 简单表达式,它通过将表达式与一组简单的表达式进行比较来确定结果
CASE 搜索表达式,它通过计算一组布尔表达式来确定结果
-- 统计男女生中未成年、成年的人数
SELECT CASE WHEN Sex=0 THEN '男' ELSE '女' END AS '性别',
SUM(CASE WHEN Age<18 THEN 1 ELSE 0 END) AS '未成年',
SUM(CASE WHEN Age>=18 THEN 1 ELSE 0 END) AS '成年'
FROM Students
GROUP BY Sex
参考 SQL总结(一)
十步完全理解SQL
1、SQL 是一种声明式语言
SQL 语言是为计算机声明了一个你想从原始数据中获得什么样的结果的一个范例。计算机会根据 SQL 所声明的内容来从数据库中挑选出符合声明的数据,而不是像传统编程思维去指示计算机如何操作。
2、SQL的语法并不按照语法顺序执行
SQL的语法顺序是:select[distinct] from where group by having union order by
SQL的执行顺序是:from where group by having select distinct union order by
- from才是SQL语句执行的第一步,将数据从硬盘加载到数据缓冲区
- select是在from和group by之后执行的,意味着你不能在 where 中使用在 select 中设定别名的字段作为判断条件
- 无论在语法上还是在执行顺序上, UNION 总是排在在 ORDER BY 之前
3、SQL语言的核心是对表的引用
FROM语句的“输出”是一张联合表,来自于所有引用的表在某一维度上的联合。
从集合论(关系代数)的角度来看,一张数据库的表就是一组数据元的关系,而每个 SQL 语句会改变一种或数种关系,从而产生出新的数据元的关系(即产生新的表)
4、灵活引用表能使SQL语句变得更强大
select * from Table1 a Inner join Table2 b On a.index = b.index
-- 等效于
select * from Table1 a,Table2 b where a.index = b.index
尽量不要使用逗号来代替 JOIN 进行表的连接,这样会提高你的 SQL 语句的可读性,并且可以避免一些错误。
5、SQL语句中推荐使用表连接
JOIN的好处:
安全, JOIN 和要连接的表离得非常近,这样就能避免错误。
更多连接的方式,JOIN 语句能去区分出来外连接和内连接等。
记着要尽量使用 JOIN 进行表的连接,永远不要在 FROM 后面使用逗号连接表。
6、SQL语句中不同的连接操作
SQL语句中,表连接的方式从根本上分为五种:EQUI JOIN、SEMI JOIN、ANTI JOIN,CROSS JOIN,DIVISION
EQUI JOIN包含两种连接方式:
- INNER JOIN(或者是JOIN)
- OUTER JOIN(包括:LEFT,RIGHT,FULL OUTER JOIN)
author JOIN book ON author.id = book.author_id
author LEFT OUTER JOIN book ON author.id = book.author_id
SEMI JOIN:这种连接关系在SQL中有两种表现方式:使用IN或者EXISIT
-- Using IN
FROM author
WHERE author.id IN (SELECT book.author_id FROM book)
-- Using EXISTS
FROM author
WHERE EXISTS (SELECT 1 FROM book WHERE book.author_id = author.id)
ANTI JOIN:在 IN 或者 EXISTS 前加一个 NOT 关键字就能使用这种连接
-- Using IN
FROM author
WHERE author.id NOT IN (SELECT book.author_id FROM book)
-- Using EXISTS
FROM author
WHERE NOT EXISTS (SELECT 1 FROM book WHERE book.author_id = author.id)
CROSS JOIN(交叉联合):两个连接的表的乘积:即将第一张表的每一条数据分别对应第二张表的每条数据
author CROSS JOIN book
DIVISION 的确是一个怪胎。简而言之,如果 JOIN 是一个乘法运算,那么 DIVISION 就是 JOIN 的逆过程。
理解内连接、外连接的区别
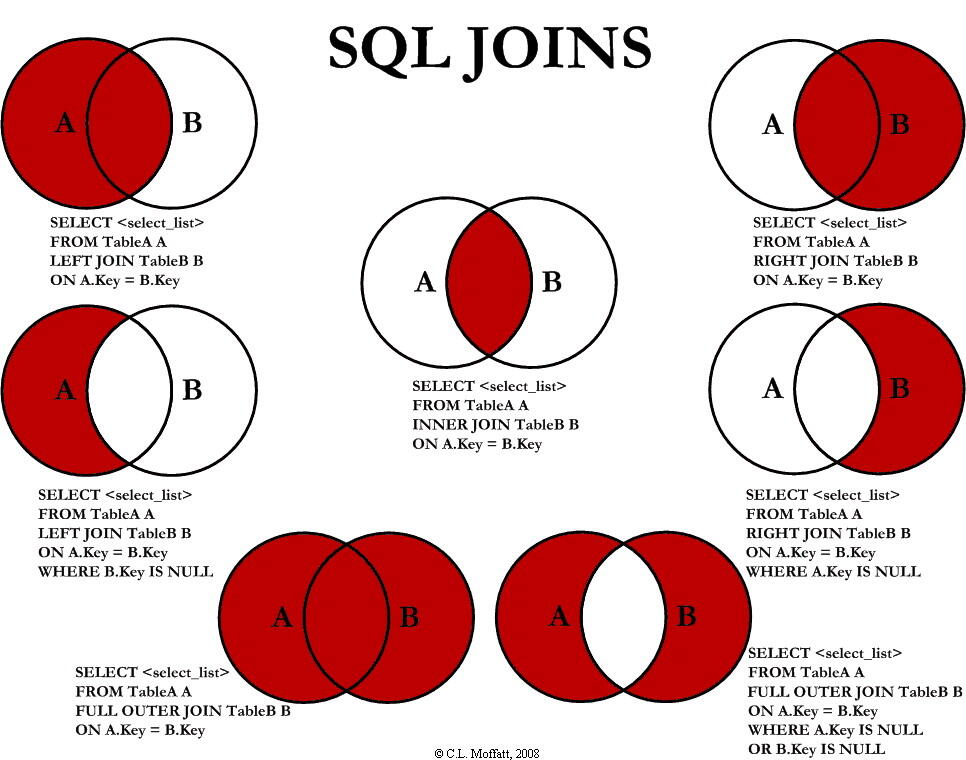
7、SQL中如同变量的派生表
派生表就是在括号中的子查询
-- Get authors' first and last names, and their age in days
SELECT first_name, last_name, age
FROM (
SELECT first_name, last_name, current_date - date_of_birth age
FROM author
)
-- If the age is greater than 10000 days
WHERE age > 10000
大体上来说 SQL 语句就是对表的引用,而并非对字段的引用。
8、SQL 语句中 GROUP BY 是对表的引用进行的操作
注意:当你应用 GROUP BY 的时候, SELECT 后没有使用聚合函数的列,都要出现在 GROUP BY 后面
SELECT A.x, A.y, SUM(A.z)
FROM A
GROUP BY A.x, A.y
9、SQL 语句中的 SELECT 实质上是对关系的映射
SELECT 语句有很多特殊的规则,至少你应该熟悉以下几条
- 你仅能够使用那些能通过表引用而得来的字段;
- 当你的语句中没有 GROUP BY 的时候,可以使用开窗函数代替聚合函数;
- 当你的语句中没有 GROUP BY 的时候,你不能同时使用聚合函数和其它函数;
10、SQL 语句中的几个简单的关键词: DISTINCT , UNION , ORDER BY 和 OFFSET
集合运算
-
DISTINCT 在映射之后对数据进行去重
-
UNION 将两个子查询拼接起来并去重
-
UNION ALL 将两个子查询拼接起来但不去重
-
EXCEPT 将第二个字查询中的结果从第一个子查询中去掉
-
INTERSECT 保留两个子查询中都有的结果并去重
排序运算(ORDER BY,OFFSET…FETCH)
参考 十步完全理解 SQL