List概览
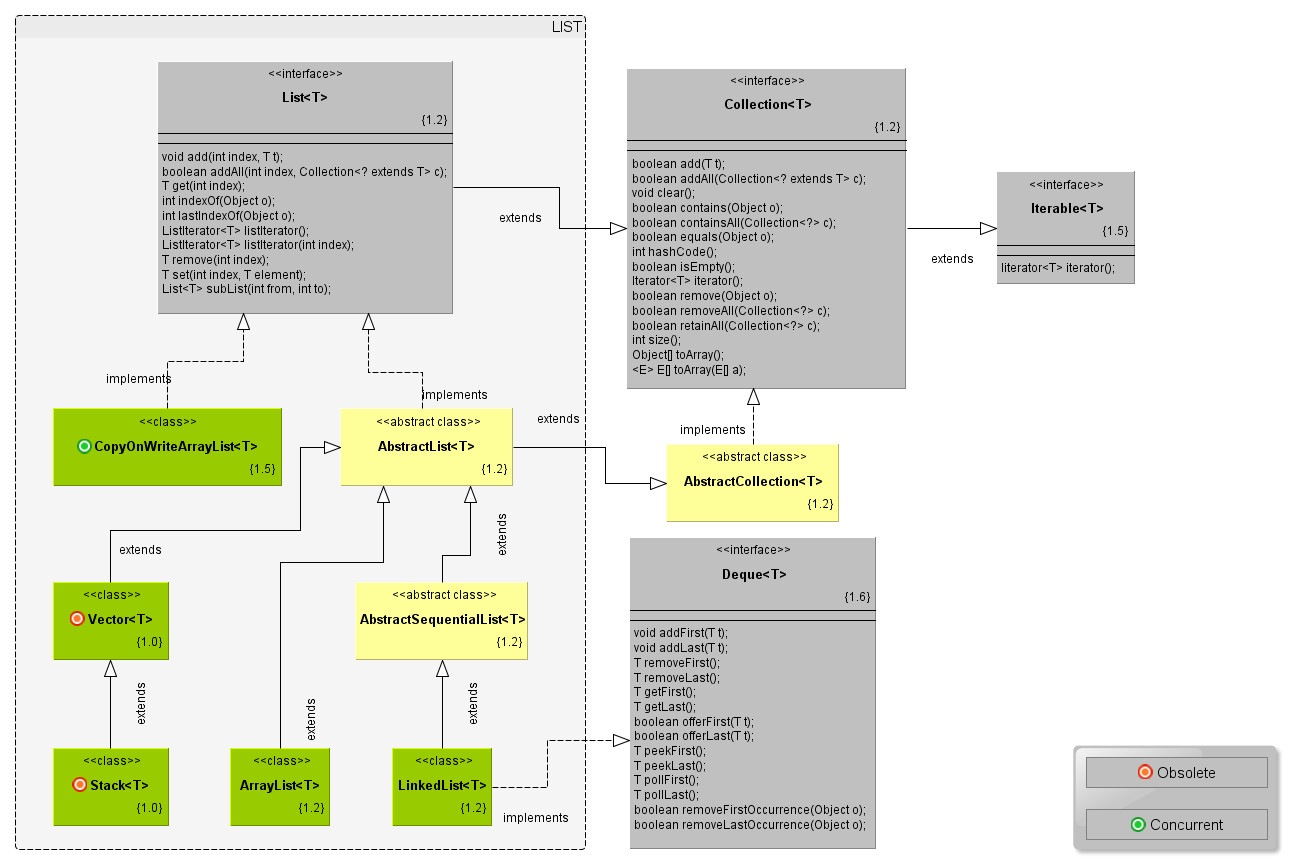
在List中最常用的两个类就数ArrayList和LinkedList。他们两个的实现代表着数据结构中的两种典型:线性表和链表。在这里,这个线性表是可以根据需要自动增长的。Java的库里面默认没有实现单链表,LinkedList实际上是一个双链表。
ArrayList
ArrayList是内部基于数组的线性表实现,使用transient Object[] elementData; // non-private to simplify nested class access数组变量来保存元素,使用private int size;来保存当前list的长度。
构造
无参构造函数,默认是空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA,为了延迟初始化;有参函数则可以传入list大小和一个集合类来初始化数组。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
增加元素
增加元素的方法有若干个,包括add(E e),add(int index, E element),addAll(Collection<? extends E> c)等方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
如果增加元素到数组里会导致里面保存元素的数组长度不够了,那么就需要调整数组的长度,保证它能够包含新增元素。同时,如果数组增长到极限长度Integer.MAX_VALUE,这时候就需要异常处理。
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
在我们原来的数组长度不能满足要求的时候,我们首先考虑将数组增加到原来的1.5倍,如 int newCapacity = oldCapacity + (oldCapacity » 1);这句所描述。当然,如果增加到原来1.5倍发现长度还是不能满足需要的时候,我们就进行了后续的比较。首先将数组长度设置为期望的参数长度,然后和我们设置的最大长度比较。如果没有这个最大长度MAX_ARRAY_SIZE大的话,就直接分配这么长的数组。否则就分配最大长度的数组来尝试,这个最大的长度就是Integer.MAX_VALUE。
删除元素
- public E remove(int index) :删除单个元素
- public boolean remove(Object o) :删除单个元素
- protected void removeRange(int fromIndex, int toIndex):删除区段内元素
- public boolean removeAll(Collection<?> c):删除集合中的共同元素
- public void clear():删除所有元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,numMoved);
elementData[--size] = null; // clear to let GC do its work
}
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
我们先看remove(int index)这个方法的实现。在删除元素之前,我们先用rangeCheck方法判断指定的参数是否合法。因为有可能我们传入的参数不是在0到数组长度之间的。在找到要删除的元素之后,从它开始后面的元素向前移一位来实现元素的删除。这里int numMoved = size - index - 1;这一句指定了数组拷贝的长度。因为是要从index + 1这个元素到size - 1之间包括头尾这两个元素的一段往前挪一位,所以要移动的元素数目为size - index -1。
remove(Object o)这个方法的实现考量是不一样的。因为它是要从数组中删除一个指定的元素,所以要删除它之前我们必须要遍历整个数组来找到它。如果根本就找不到,那根本就什么都不需要做了。如果找到这个要删除的元素,则和前面一个方法的处理流程一样,后面一个元素到末尾的都往前移一位。
clear方法显然非常的简单。它将数组里所有引用都置为null,这样做是防止内存泄露,然后再将数组长度设置为0。
removeRange方法的参数指定了起始到终止的数据范围,所以实现的方法只要把终止元素到数组末尾的元素挪到原来起始位置的后面,再把空缺的那部分置空就可以了。
查找元素
查找元素主要包含有如下几个方法:contains, indexOf, lastIndexOf。最核心的就是indexOf方法:
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
这部分的代码非常简单,就是从头往后一直遍历和比较元素,找到相等的就返回。只是要考虑目的元素为null的情况。lastIndexOf也很类似,只是从数组的末尾往前遍历,寻找目的元素。
LinkedList
LinkedList 同时实现了List< E >和Deque< E >两个接口,所以也满足先进先出的队列特性。此外,后面会提到LinkedList还提供了栈的特性。
在JDK里,专门定义了一个私有内部类,它也决定了LinkedList是一个双向链表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
由于Node是私有静态内部类,所以仅限于在LinkedList内部使用。LinkedList里包含了三个元素,transient int size = 0;链表长度,transient Node<E> first;链表头,transient Node<E> last;链表尾。
linkedList和ArrayList有很多在元素的添加、删除查找上面接口相同的方法。和ArrayList比较起来的区别在于它是通过内部遍历链表再来进行操作的。这部分就针对几个典型的操作挑几个来分析。
构造函数
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
public LinkedList() {
}// 空
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
添加元素
添加元素里比较典型的有linkFirst和linkLast,表示在链表头之前和链表尾部添加元素。add(E e)默认是添加在链表尾部。
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public boolean add(E e) {
linkLast(e);
return true;
}
这里要考虑的一个点就是不管是在头之前还是在尾之后添加元素,要注意判断头尾节点为空的情况。同时,在更新完之后对长度值加1。LinkedList有一个比ArrayList好的地方,因为它可以很灵活的添加元素而不需要做大的调整。在ArrayList里面如果元素数量足够大了要调整和拷贝元素。
删除元素
删除元素里面典型的两个操作是removeFirst()和removeLast()。
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
在移除元素的时候,首先要判断first和last是否为空。当他们为空的时候意味着整个链表都是空的。还有一种需要考虑的情况就是如果整个链表只有一个元素,在删除了之后,实际上链表就空了。这里需next == null;和 prev == null;这两句就是分别在删除头和尾元素时判断删除后链表为空的条件。
LinkedList和ArrayList很多相同的部分比如索引数据,他们的实现都比较简单,这里就不再一一列举。
栈和队列特性
LinkedList实现了一个Deque的接口,这个接口定义了队列的实现规范。在后面一篇文章里讨论队列实现的时候,我们会重点讲述,这里就暂时省略。
另外,LinkedList还有一个有意思的特性,它本身也实现了一个栈的规范。和我们前面通过继承vector来实现Stack不一样。它采用每次直接在链表头之前添加元素来实现push方法,删除链表头元素实现pop方法。和栈实现相关的方法实现如下:
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
public void push(E e) {
addFirst(e);
}
public E pop() {
return removeFirst();
}
这样,以后我们如果要使用栈的话,除了声明Stack类以外,把LinkedList当成Stack使也是可行的。
Stack
栈的数据结构特性即后进先出,Stack类在java.util包里,通过继承Vector,Stack类可以容易实现。
stack里实现的方法
- empty:判断stack是否为空,返回boolean
- peek:返回栈顶元素,E
- pop:返回栈顶元素并删除,E
- push:元素压栈,E
- search:返回最靠近顶端的目标元素到顶端的距离
empty
如果要判断stack是否为空,就需要有一个变量来计算当前栈的长度,如果该变量为0,则表示该栈为空
public boolean empty() {
return size() == 0;
}
Vector已经实现了size()方法。在Vector里面有一个变量elementCount来表示容器里元素的个数。如果为0,则表示容器空。
public synchronized int size() {
return elementCount;
}
peek
peek是指的返回栈顶端的元素,我们对栈本身不做任何的改动。如果栈里有元素的话,我们就返回最顶端的那个。而该元素的索引为栈的长度。如果栈为空的话,则要抛出异常:
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
这个elementAt方法也是Vector里面的一个实现。在Vector里面,实际上是用一个elementData的Object数组来存储元素的。所以要找到顶端的元素无非就是访问栈最上面的那个索引。
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
pop
pop方法就是将栈顶的元素弹出来,如果栈里有元素,就取最顶端的那个,否则就要抛出异常:
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
在这里,判断是否可以取栈顶元素在peek方法里实现了,也将如果栈为空则抛异常的部分包含在peek方法里面。这里有必要注意的一个细节就是,在通过peek()取到顶端的元素之后,我们需要用removeElementAt()方法将最顶端的元素移除。为什么要移除呢?我们反正有一个elementCount来记录栈的长度,不管它不是也可以吗?只要我们一直在用着stack,那么stack里面所有关联的元素就都别想释放了。这样运行时间一长就会导致内存泄露的问题。
vector里的removeAt方法
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
elementData[elementCount] = null; /* to let gc do its work */
}
这个方法实现的思路也比较简单。就是用待删除元素的后面元素依次覆盖前面一个元素。这样,就相当于将数组的实际元素长度给缩短了。因为这里这个移除元素的方法是定义在vector中间,它所面对的是一个更加普遍的情况,我们移除的元素不一定就是数组尾部的,所以才需要从后面依次覆盖。如果只是单纯对于一个栈的实现来说,我们完全可以直接将要删除的元素置为null就可以了。
push
push的操作也比较直观。我们只要将要入栈的元素放到数组的末尾,再将数组长度加1就可以了。
public E push(E item) {
addElement(item);
return item;
}
这里,addElement方法将后面的细节都封装了起来。如果我们更加深入的去考虑这个问题的话,我们会发现几个需要考虑的点。1. 首先,数组不会是无穷大的 ,所以不可能无限制的让你添加元素下去。当我们数组长度到达一个最大值的时候,我们不能再添加了,就需要抛出异常来。2. 如果当前的数组已经满了,实际上需要扩展数组的长度。常见的手法就是新建一个当前数组长度两倍的数组,再将当前数组的元素给拷贝过去。前面讨论的这两点,都让vector把这份心给操了。
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
看到这部分代码的时候,我不由得暗暗叹了口气。真的是拔了萝卜带出泥。本来想看看stack的细节实现,结果这些细节把vector都深深的出卖了。在vector中间有几个计数的变量,elementCount表示里面元素的个数,elementData是保存元素的数组。所以一般情况下数组不一定是满的,会存在着elementCount <= elementData.length这样的情况。这也就是为什么ensureCapacityHelper方法里要判断一下当新增加一个元素导致元素的数量超过数组长度了,我们要做一番调整。这个大的调整就在grow方法里展现了。
grow方法和我们所描述的方法有点不一样。他不一样的一点在于我们可以用一个capacityIncrement来指示调整数组长度的时候到底增加多少。默认的情况下相当于数组长度翻倍,如果设置了这个变量就增加这个变量指定的这么多。
search
search这部分就相当于找到一个最靠近栈顶端的匹配元素,然后返回这个元素到栈顶的距离。
public synchronized int search(Object o) {
int i = lastIndexOf(o);
if (i >= 0) {
return size() - i;
}
return -1;
}
对应在vector里面的实现也相对容易理解:
public synchronized int lastIndexOf(Object o) {
return lastIndexOf(o, elementCount-1);
}
public synchronized int lastIndexOf(Object o, int index) {
if (index >= elementCount)
throw new IndexOutOfBoundsException(index + " >= "+ elementCount);
if (o == null) {
for (int i = index; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = index; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
这个lastIndexOf的实现无非是从数组的末端往前遍历,如果找到这个对象就返回。如果到头了,还找不到对象呢…不好意思,谁让你找不到对象的?活该你光棍,那就返回个-1吧。
Vector
在前面对stack的讨论和分析中,我们几乎也把vector这部分主要的功能以及实现给涵盖了。而Vector内部的实现是采用一个object的array,原理和ArrayList很像,和ArrayList的不同在于它对元素的访问都用synchronized修饰,也就是说它是线程安全的,在多线程的环境下,我们可以使用它。
CopyOnWriteArrayList
Copy-On-Write简称COW,是一种用于程序设计中的优化策略。其基本思路是,从一开始大家都在共享同一个内容,当某个人想要修改这个内容的时候,才会真正把内容Copy出去形成一个新的内容然后再改,这是一种延时懒惰策略。从JDK1.5开始Java并发包里提供了两个使用CopyOnWrite机制实现的并发容器,它们是CopyOnWriteArrayList和CopyOnWriteArraySet。CopyOnWrite容器非常有用,可以在非常多的并发场景中使用到。
什么是CopyOnWrite容器
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
构造函数
类似ArrayList采用数组实现,lock用来在写操作时加锁。
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
读操作
读的时候不需要加锁,如果读的时候有多个线程正在向ArrayList添加数据,读还是会读到旧的数据,因为写的时候不会锁住旧的ArrayList。
public boolean isEmpty() {
return size() == 0;
}
public int indexOf(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length);
}
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
写操作
public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
//复制出新数组
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)
newElements = Arrays.copyOf(elements, len + 1);
else {
newElements = new Object[len + 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index, newElements, index + 1,numMoved);
}
//把新元素添加到新数组里
newElements[index] = element;
//把原数组引用指向新数组
setArray(newElements);
} finally {
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}
CopyOnWrite并发容器用于读多写少的并发场景。比如白名单,黑名单,商品类目的访问和更新场景。
public class BlackListServiceImpl {
private static CopyOnWriteMap<String, Boolean> blackListMap = new CopyOnWriteMap<String, Boolean>(1000);
public static boolean isBlackList(String id) {
return blackListMap.get(id) == null ? false : true;
}
public static void addBlackList(String id) {
blackListMap.put(id, Boolean.TRUE);
}
public static void addBlackList(Map<String,Boolean> ids) {
blackListMap.putAll(ids);
}
}
使用CopyOnWriteMap需要注意两件事情:
- 减少扩容开销。根据实际需要,初始化CopyOnWriteMap的大小,避免写时CopyOnWriteMap扩容的开销。
- 使用批量添加。因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用上面代码里的addBlackList方法。
CopyOnWrite容器有很多优点,但是同时也存在两个问题,即内存占用问题和数据一致性问题。所以在开发的时候需要注意一下。
- 内存占用问题。因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
- 数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。