Set概览
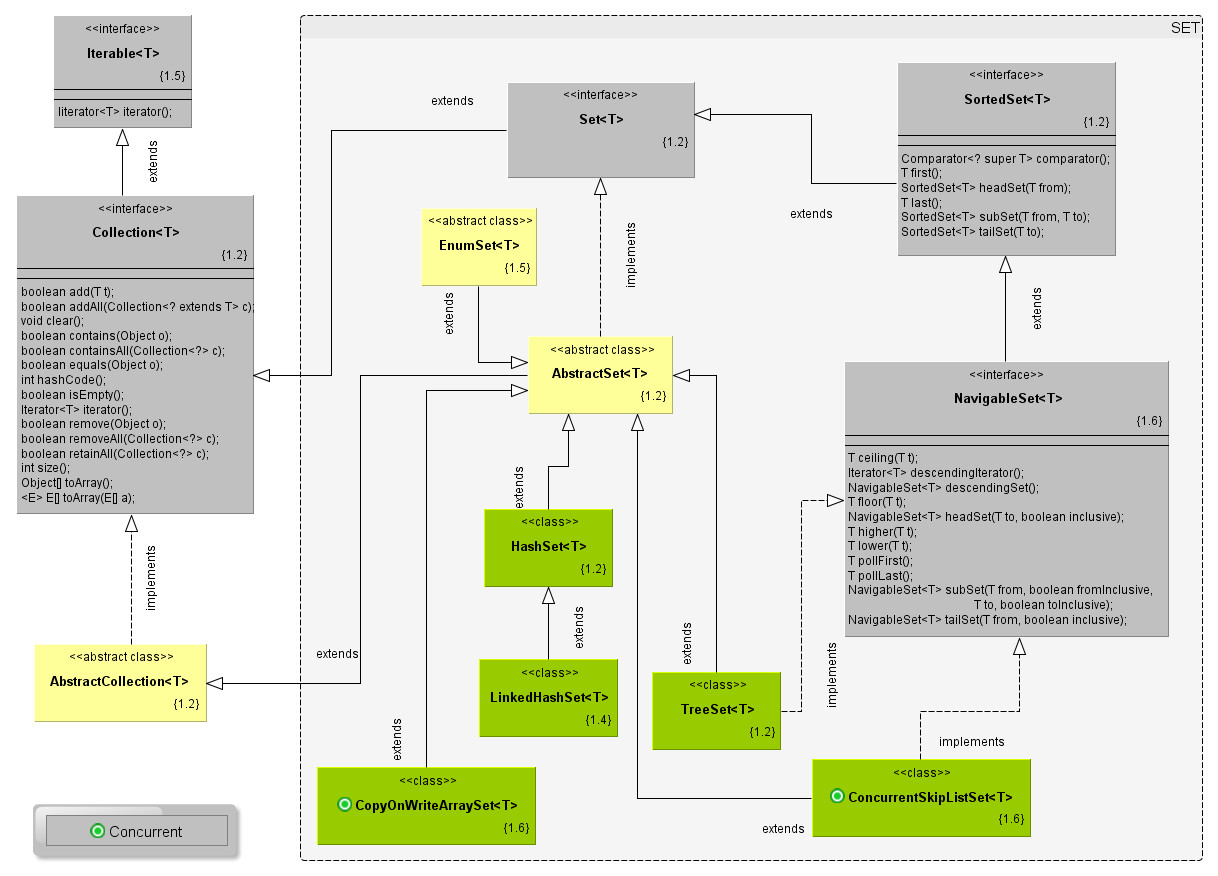
在常用的集合类型中,HashSet, TreeSet等具体的实现往往不一样。比如说HashSet本身的实现是引用了HashMap作为内部的元素。如果我们仔细检查他们的结构实现,会发现有的类型我们也可以通过foreach的循环来遍历。这是因为他们有的在实现Set定义接口的范围同时也继承了实现Collection接口的部分。可以说是两者兼有之。
在上面这些集合类型中,基于Hash表实现的主要有HashSet, LinkedHashSet。基于红黑树实现的有TreeSet.另外,CopyOnWriteArraySet内部的实现是采用了一个CopyOnWriteArrayList,这种数据结构有一个比较有意思的实现。对它调用某些增删元素的方法会产生一个全新的对象。这充分利用了immutable对象的实现思路,在并行程序的开发中有一定的应用。
Set接口
Set接口里面主要定义了常用的集合操作方法,包括添加元素,判断元素是否在里面和对元素过滤。常用的几个方法如下:
| 方法名 | 方法详细定义 | 说明 |
|---|---|---|
| contains | boolean contains(Object o); | 判断元素是否存在 |
| add | boolean add(E e); | 添加元素 |
| remove | boolean remove(Object o); | 删除元素 |
| retainAll | boolean retainAll(Collection<?> c); | 过滤元素 |
HashSet
HashSet是基于HashMap实现的,在它内部有如下的定义:
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
在它里面放置的元素都应到map里面的key部分,而在map中与key对应的value用一个Object()对象保存。因为内部是大量借用HashMap的实现,它本身不过是调用HashMap的一个代理,这些基本方法的实现就显得很简单:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
HashMap中Key是独一无二的,符合集合的定义。
具体实现参考HashMap。
TreeSet
这里比较有意思的地方是,似乎有Map和Set的地方,Set几乎都成了Map的一个马甲。此话怎讲呢?在前面一篇讨论HashMap和HashSet的详细实现讨论里,我们发现HashSet的详细实现都是通过封装了一个HashMap的成员变量来实现的。这里,TreeSet也不例外。我们先看部分代码:
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<?> cc = set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
主要的构造函数就两个,一个是默认的无参数构造函数和一个比较器构造函数,他们内部的实现都是使用的TreeMap,而其他相关的构造函数都是通过调用这两个来实现的,故其底层使用的就是TreeMap。既然TreeSet只是TreeMap的一个马甲,我们就只要重点关注一下TreeMap里面的实现好了。
参考TreeMap
LinkedHashSet
LinkedHashSet继承自HashSet,构造函数调用了HashSet的三元构造函数,创建一个LinkedHashMap,基于链表实现。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
//super调用HashSet的构造函数
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
CopyOnWriteArraySet
private final CopyOnWriteArrayList<E> al;
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e);
}
//CopyOnWriteArrayList的addIfAbsent方法
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
内部采用CopyOnWriteArrayList实现,插入的时候确定不存在才插入,保证集合的特性。
ConcurrentSkipListSet
private final ConcurrentNavigableMap<E,Object> m;
public ConcurrentSkipListSet() {
m = new ConcurrentSkipListMap<E,Object>();
}
public boolean add(E e) {
return m.putIfAbsent(e, Boolean.TRUE) == null;
}
public boolean remove(Object o) {
return m.remove(o, Boolean.TRUE);
}
内部采用ConcurrentSkipListMap实现,具体实现参考Map篇
参考:java集合类深入分析之HashSet, HashMap篇